Introdução a Arquitetura Hadoop
Fala pessoal blz? No post de hoje vamos trocar uma ideia sobre a Arquitetura de Big Data Hadoop. E aí, bora aprender algo novo?
O que é Hadoop?
O Hadoop é um ecossistema/estrutura de software open source criado para armazenar de forma massiva dados dos mais diversos tipos e executar aplicações distribuídas (i.e., tarefas ocorrendo ao mesmo tempo) em clusters (i.e., computadores conectados entre si) de hardwares comuns e de baixo custo.
A ideia por traz do Hadoop é fornecer um ambiente escalável no qual, quando você vai necessitando de mais espaço e poder computacional você vai adicionando mais máquinas ao seu cluster Hadoop.
E importante ressaltar que o Hadoop é tolerante a falhas e por causa disso ele replica os dados armazenados no seu sistema de arquivos para evitar que isso aconteça durante o uso de alguma aplicação sobre os dados utilizados.
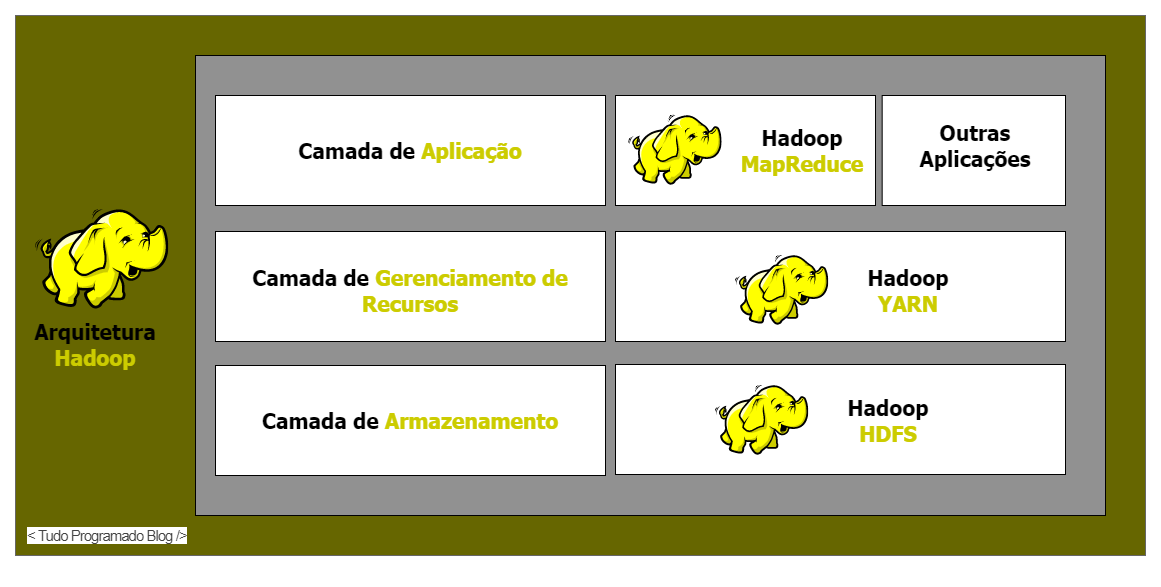
O Hadoop consiste desses 3 componentes core para o seu funcionamento:
- Hadoop Distributed File System (HDFS) – É a camada de armazenamento do Hadoop.
- Map-Reduce – É a camada de processamento de dados do Hadoop.
- YARN – É a camada de gerenciamento de recursos do Hadoop.
A seguir eu vou falar sobre as 3 camadas/componentes que eu penso quando escuto falar no Hadoop, acredito serem extramente importantes para o funcionamento desse ecossistema.
O que é o HDFS?
Na camada de armazenamento temos o HDFS que é um sistema de arquivos distribuído, projetado para armazenar arquivos muito grandes, com padrão de acesso aos dados streaming (i.e., dados em streaming, são dados gerados continuamente por milhares de fontes de dados e.g., Internet das Coisas) e batch (i.e., em lote), utilizando clusters de servidores facilmente encontrados no mercado e de baixo ou médio custo.
É importante ressaltar que o Hadoop não deve ser utilizado para aplicações que precisem de acesso rápido a um determinado registro e sim para aplicações nas quais é necessário ler uma quantidade massiva (i.e., muito grande) de dados.
Quando utilizamos o Hadoop outra questão que deve ser analisada é que ele não deve ser utilizado para ler muitos arquivos pequenos, isso irá acarretar no mal uso de armazenamento e irá gerar um processamento mais lento tendo em vista o overhead de memória envolvido.
O HDFS possui o conceito de blocos, assim como no sistema Unix, mas seus blocos normalmente têm tamanho de 128MB. Um arquivo muito grande pode ter blocos armazenados em mais de um local (i.e., sistema de tolerância a falhas). Com este conceito de blocos de tamanho fixo fica mais fácil calcular as necessidades de armazenamento para cada projeto que precise utilizar o seu cluster Hadoop. Essa representação de alocação de recurso no HDFS fica mais clara com o exemplo na Figura 1. Na Figura 1 é utilizado um arquivo de exemplo com a extensão .txt que tem o tamanho de 612 MB. Devido ao tamanho do arquivo ele é quebrado em 5 partes onde, 4 partes usam 128 MB e somente a ultima parte tem o tamanho 100 MB sendo o menor bloco. Isso ocorre devido ao formato e tamanho do armazenato configurados para o seu ambiente hadoop.
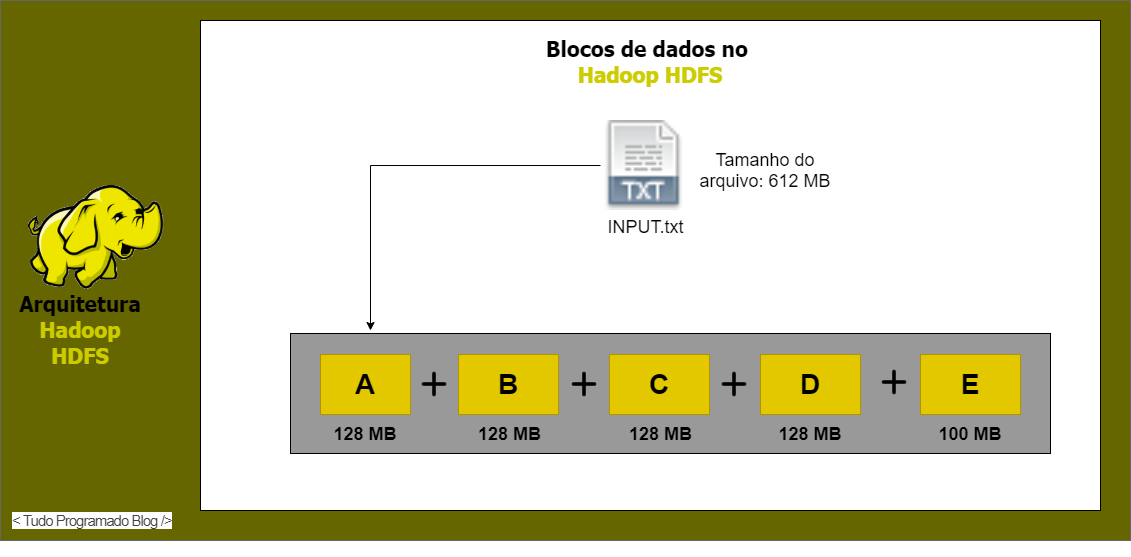 Figura 1: Exemplo de alocação de recursos no HFDS para um arquivo com tamanho de 612 MB - Imagem adaptada de: https://data-flair.training/blogs/data-block/
Figura 1: Exemplo de alocação de recursos no HFDS para um arquivo com tamanho de 612 MB - Imagem adaptada de: https://data-flair.training/blogs/data-block/
O HDFS possui 2 tipos de nós sendo eles o Master (ou Namenode) e Worker (ou Datanode). O Master armazena informações da distribuição de arquivos e os seus respectivos metadados. O Worker armazena os dados propriamente ditos.
MapReduce e Outras Aplicações
Na camada de processamento de dados temos o MapReduce que é um modelo de programação distribuída (i.e., paralela) proposto pelo Google para para facilitar o processamento de grandes volumes de dados (i.e., Big Data).
O modelo de programação MapReduce consiste na construção de um programa formado por duas operações basicas sendo elas o Map e o Reduce. O processo de Map recebe um par chave e valor e gera também um conjunto intermediário de dados no formato chave e valor. O processo de reduce é executado para cada chave intermediária com todos os conjuntos de valores intermediários associados àquela chave combinados. De forma sucinta o processo de map é usado para encontrar algo, e o processo de reduce é utilizado para fazer a sumarização do resultado.
Na Figura 2 é ilustrado o processo de Map e Reduce em um problema de contagem de letras. Nesse exemplo é realizada a contagem de quantas vezes alguma letra se repete dentro de um texto qualquer.
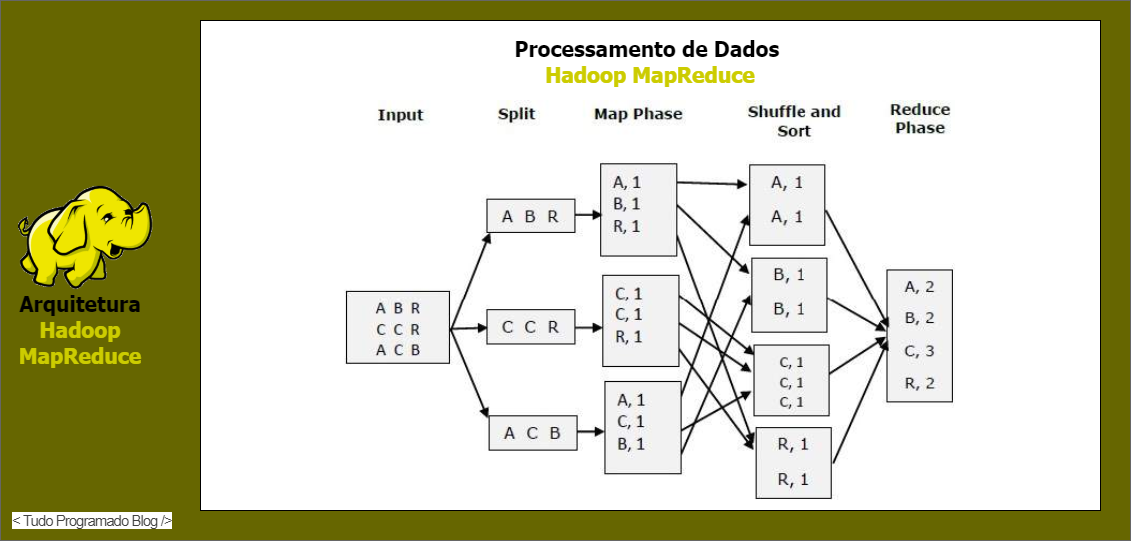 Figura 2: Exemplo de execução do processo de MapReduce sobre um conjunto de dados texto - Imagem adaptada de: https://pt.itbrain.online/tutorial/map_reduce/map_reduce_quick_guide/
Figura 2: Exemplo de execução do processo de MapReduce sobre um conjunto de dados texto - Imagem adaptada de: https://pt.itbrain.online/tutorial/map_reduce/map_reduce_quick_guide/
Você sabia que o modelo de processamento MapReduce é indicado para problemas mais simples de Big Data. Ele processa os dados em memória secundário o que acaba sendo algo lento. Nesse caso o MapReduce é indicado para problemas analiticos onde, o tempo de resposta não precise ser imediato para tomada de decisão. O MapReduce é também indicado quando sua memória primaria é inferior ao tamanho do dataset que você precisa processar com seu Cluster Hadoop.
Ainda sobre MapReduce, irei fazer um outro post somente sobre isso com código para simplificar o conceito de forma mais clara e objetiva.
O que é o YARN?
Na camada de gerenciamento de recursos temos o Yet Another Resource Negotiator (YARN). O princípio básico por trás do YARN é separar o gerenciamento de recursos e a função de planejamento/monitoramento de tarefas em daemons (i.e., em segundo plano/background) separados.
Na Figura 3 ilustra-se o processo de envio de um job para o cluster hadoop e como o YARN realiza o gerenciamento desse job em relação ao nó master e workers disponiveis no cluster para processar o job que acaba de chegar. A seguir falaremos sobre os recursos gerenciados pelo YARN referentes ao processo ilustrado na Figura 3.
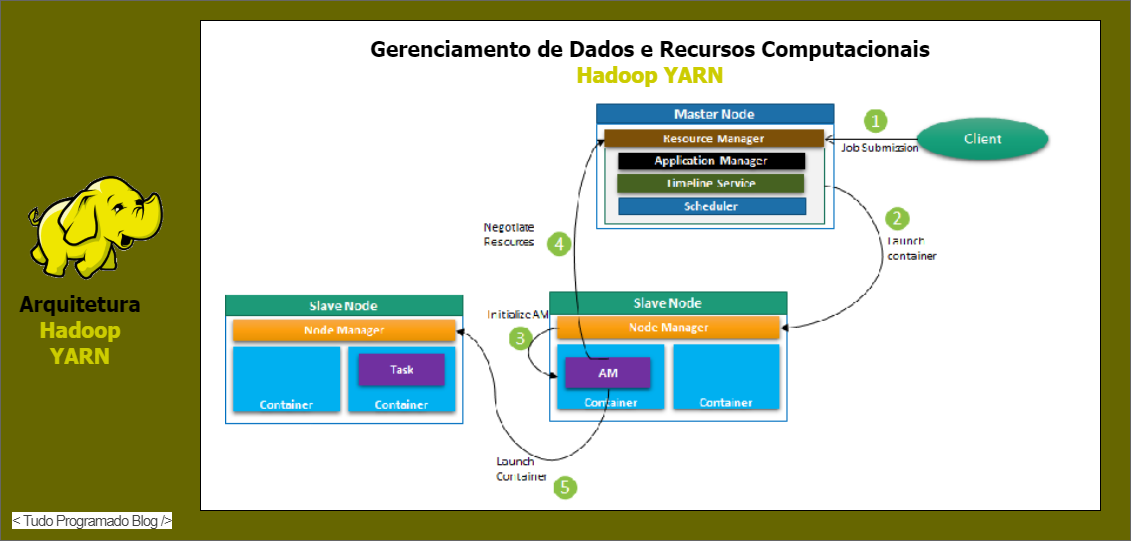 Figura 3: Exemplo fluxo de execução realizado pelo gerenciador de recursos YARN - Imagem adaptada de: https://subscription.packtpub.com/book/big_data_and_business_intelligence/9781788999830/5/ch05lvl1sec42/understanding-yarn-architecture
Figura 3: Exemplo fluxo de execução realizado pelo gerenciador de recursos YARN - Imagem adaptada de: https://subscription.packtpub.com/book/big_data_and_business_intelligence/9781788999830/5/ch05lvl1sec42/understanding-yarn-architecture
No YARN, há um gerenciador de recursos global (i.e., ResourceManager) e um gerenciador de aplicativos (i.e., ApplicationMaster) por aplicativo. Um aplicativo pode ser uma única tarefa ou uma DAG de tarefas (i.e., uma tarefa composta por sub-tarefas).
Dentro da estrutura YARN, temos duas daemons sendo elas o ResourceManager e NodeManager. O ResourceManager gerenncia recursos entre todos os aplicativos concorrentes no sistema. A função do NodeManger é monitorar o uso de recursos por container e relatar o mesmo ao ResourceManger. Os recursos são como a CPU, memória, disco, rede e assim por diante.
O ApplcationMaster negocia recursos com ResourceManager e trabalha com NodeManger para executar e monitorar cada tarefa.
O ResourceManger tem dois componentes importantes sendo eles o Scheduler e ApplicationManager.
Scheduler
O Scheduler é o responsável por alocar recursos para vários aplicativos. Este é um agendador puro, pois não realiza rastreamento de status para os aplicativos. Também não reagenda as tarefas que falham devido a erros de software ou hardware. O agendador aloca os recursos com base nos requisitos dos aplicativos.
ApplicationManager
Funcões do ApplicationManager:
- Aceita o envio de tarefas;
- Negocia o primeiro container para a execução do ApplicationMaster. Um container incorpora elementos como a CPU, memória, disco e rede.
- Reinicia o container ApplicationMaster em caso de falha.
Funções do ApplicationMaster:
- Negocia o container de recursos do Scheduler.
- Rastreia o status do container de recursos.
- Monitora o progresso dos aplicativos.
Podemos escalar o YARN por meio de vários nós atrávez do recurso YARN Federation. Esse recurso nos permite vincular vários clusters YARN em um único cluster massivo. Isso permite o uso de clusters independentes, agrupados para uma tarefa muito grande (i.e., também conhecido como filas de processamento específicas).
Quais são os desafios em usar o Hadoop?
A programação de MapReduce não é uma boa solução para todos os problemas
Ela é uma boa alternativa para tarefas simples e problemas que podem ser divididos entre unidades independentes, mas não é eficiente para tarefas de inteligência analítica iterativas e interativas. MapReduce foi desenvolvido focado para trabalhar com arquivos. Devido aos nós não se comunicarem diretamente, exceto através de operações de map e reduce, algoritmos iterativos precisam de diversas etapas de map e reduce para se completarem. Isso cria muitos arquivos entre as fases de MapReduce e não é eficiente para computação analítica avançada.
Há uma lacuna de talento amplamente notada referente aos profissionais de Big Data
Em pleno ano de 2021 ainda pode ser difícil encontrar bons programadores iniciantes que tenham habilidades suficientes em Java para serem produtivos usando o modelo MapReduce. Esse é um dos motivos pelos quais os fornecedores de solução Hadoop estão buscando alternativas para incluir tecnologias like SQL (i.e., relacional) em Hadoop. É muito mais fácil encontrar programadores com habilidades em SQL do que em programação MapReduce (i.e., programação distribuída).
Esse é um bom mercado para se encontrar trabalho pois ainda faltam profissionais capacitados.
Gestão e governança de dados completos do ínicio ao fim
O Hadoop não possui ferramentas completas e fáceis de usar para o gerenciamento de dados, limpeza de dados, governança e gestão de metadados. Também faltam ferramentas para a qualidade e padronização de dados por ser um ambiente que trabalha com dados complexos em geral.
Para mais detalhes e complementos sobre o Hadoop, você poder acessar o site do Apache Hadoop e ler sobre os tópicos discutidos nesse post.
Espero ter ajudado você caro leitor(a) a entender um pouco mais sobre o que é o Hadoop e como ele funciona, de forma simples, por mais complexo que ele seja. Se você curtiu esse post, curta e compartilhe com os amigos.